/^[Rr]ex's Blog$/
rex's personal programming practice posts
rex
Search
Categories
New Comments
Tag Cloud
Links
Hot Posts
Counter
Meta
中缀表达式转后缀表达式之桟操作版
感觉这个小问题还挺有用的。我在研究正则表达式源码时又遇到一次。于是使用紙笔写个程序,演算无误。打开清华版的数据结构一书113页,思路暗同。借用了清华书的isp与icp函数。
c语言扑克洗牌
重新写的程序。每次洗出一张,放在最后,剩下的牌重新洗,直至最后一张。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | #include<stdio.h>#include<time.h>int N=54;char * pk[]={"黑桃A","黑桃2","黑桃3","黑桃4","黑桃5","黑桃6","黑桃7","黑桃8","黑桃9","黑桃10","黑桃J","黑桃Q","黑桃K","红桃A","红桃2","红桃3","红桃4","红桃5","红桃6","红桃7","红桃8","红桃9","红桃10","红桃J","红桃Q","红桃K","草花A","草花2","草花3","草花4","草花5","草花6","草花7","草花8","草花9","草花10","草花J","草花Q","草花K","方块A","方块2","方块3","方块4","方块5","方块6","方块7","方块8","方块9","方块10","方块J","方块Q","方块K","大王","小王"};main(){ int a[N]; int i; int temp; int p; int ten=0; unsigned int time1,time2; int m=0; for (i=0;i<N;i++) { a[i]=i; } srand((unsigned)time(NULL)); for (m=0;m<100000;m++){ for (i=N-1;i>0;i--) { temp= rand() % i; p=a[i]; a[i]=a[temp]; a[temp]=p; }} for (i=0;i<N;i++) { printf("%02d:%-5s ",i+1,pk[a[i]]); ten++; if (ten==10) { printf("\n"); ten=0; } } printf("\n");} |
贴图:

逻辑联接词之合取
c语言提供了几个位操作符,其中:
- bitwise AND operator: &
- bitwise Exclusive OR operator: ^
- bitwise Inclusive OR operator: |
其结合力是依次递减的。
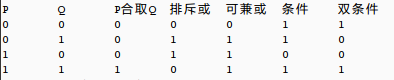
清华版《离散数学》(9787302130666),第1.2.2的合取、析取,使用c语言实现是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include<stdio.h>//条件:设p与q是两个命题,若p则q//只有当p为1,q为0时返回0值,其余返回1.tiaojian(p,q){ return (p && !q)?0:1;}//双条件:设p与q是两个命题,p当且仅当q,p的充分必要条件是q//当且仅当p与q同为0或同为1时返回1,其余返回0shuangtiaojian(p,q){ return ((p && q)||(!p && !q))?1:0;}main(){ int p,q; printf("P\tQ\tP合取Q\t排斥或\t可兼或\t条件\t双条件\n"); for(p=0;p<=1;p++) { for(q=0;q<=1;q++) { printf("%d\t%d\t%d\t%d\t%d\t%d\t%d\n",p,q,p&q,p^q,p|q,tiaojian(p,q),shuangtiaojian(p,q)); } //printf("\n"); }} |
输出结果:
紫龙书3.4.5之KMP算法fail函数
我读的紫龙书是机械工业出版社2009.01之第2版。ISBN:978-7-111-25121-7。译者是南京大学的赵建华,邓滔,戴新宇。
该书74页有个错误:
3)串s的子串(substring)是删除s的某个前缀和某个后缀之后得到的串。例如,bnana,nan和e是bnana的子串。
第一感觉这里有问题。翻开英文原书,这样写的:
3. A substring of s is obtained by deleting any prefix and any suffix from s. For instance, banana, nan, and E are substrings of banana.
就应该只是删除子串嘛,不应该是删除0个或多个符号,成为子序列那样。本书的编辑真该打屁股。
另,3.4.5,
该函数的目标是使得b1b2...bf(s)是最长的既是b1b2...bn的真前缀又是b1b2...bs的后缀的子串。
对应英文是:
The objective is that blb2...bf(s) is the longest proper prefix of b1b2...bs, that is also a suffix of b1b2bs.
读过原文之后,才勉强可理解中文翻译。中文之所以费解,是由于将“最长的”三字依英文位置给前置了。私以为放在后面会好理解一些,如:
该函数的目标是使得b1b2...bf(s)既是b1b2...bn的真前缀又是b1b2...bs的后缀的最长的子串。
就此打住,切入正题。说一下失效函数。
原书中,图3-19给出的fail函数,我使用c语言做出来了。要点是原图中的下标是以1-based,翻译为c语言要调整为0-based。程序如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #include<stdio.h>#include<string.h>int fail(const char *b){ int n=strlen(b); int t=0; int f[n+1]; f[1]=0; int s; for(s=1;s<=n;s++) { while(t>0 && b[s]!= b[t]) { t=f[t]; } if (b[s]==b[t]) { t++; f[s+1]=t; } else { f[s+1]=0; } } for (s=1;s<=n;s++) { printf("%d ",f[s]); } printf("\n");}main(){ fail("abababaab"); } |
运行该程序,解得3.4.3各串的失效函数分别为:
- abababaab->0 0 1 2 3 4 5 1 2
- aaaaaa->0 1 2 3 4 5
- abbaabb->0 0 0 1 1 2 3
紫龙书2.6习题
- 可忽略如下格式的注释//、#、/*...*/。但是如果在字串中,则无法忽略。如("../*..*/ # //")。
- 可识别<,<=,==,!=,>=,>。
- 可识别浮点数,格式如:9.22323,.323,22323.33,等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 | #!/bin/env python# -*- coding: utf-8 -*-import sysreload(sys)sys.setdefaultencoding("utf-8")#rex#2009.08.22.#不使用正则表达式,自定义下面三个函数,分别判断是否数字/字母,或者二者之一。def isDigit(d): if d>=0 and d<=9 and type(d)==int or d>='0' and d<='9' and type(d)==str: return 1 else: return 0def isLetter(l): if l>='a' and l<='z' and type(l)==str or l>='A' and l<='Z' and type(l)==str: return 1 else: return 0def isLetterOrDigit(x): if isDigit(x) or isLetter(x): return 1 else: return 0#比较关系def isComparison(x): if x=='<' or x=='>' or x=='!': return 1 else: return 0#本函数接收一个字串,#如果当前是#或//,则返回下一行的内容。def parse_float_num(str): index=0 ch=str[index] #print ch,str[index+1:] value=0 weight=10 while(isDigit(ch) or ch=='.'): if ch=='.': weight=1 index+=1 if index>len(str)-1:break ch=str[index] elif isDigit(ch): if weight==10: value=weight*value+int(ch) elif weight<10: weight*=0.1 value=value+weight*int(ch) index+=1 if index>len(str)-1:break ch=str[index] else: break return valuedef new_line(str): x=0 c=str[x] if c=='#': #print c, str[x+1] while(c!='\n'): x+=1 c=str[x] str=str[x+1:] return new_line(str) elif c=='/' and str[1]=='/': while(c!='\n'): x+=1 c=str[x] str=str[x+1:] return new_line(str) elif c=='/' and str[1]=='*': x=2 c=str[x] while c: if c=='*' and str[x+1]=='/': return new_line(str[x+2:]) x+=1 c=str[x] elif c==' ' or c=='\t' or c=='\n': x=0 while c==' ' or c=='\t' or c=='\n': x+=1 c=str[x] #print "here c:",c if str[x+1]: return new_line(str[x:]) else: return "" else: return str #定义基类token,以便被继承class Token: tag=0 def __init__(self,t): self.tag=t def tokenprint(self): print "%s"%self.tagclass Tag: NUM=256 ID=257 TRUE=258 FALSE=259 COMPARE=260#继承token,定义num类.class Num(Token): value=0 def __init__(self,v): #注意,此处override了token的自定义. Token.__init__(self,Tag.NUM) self.value=v def tokenprint(self): #自己的输出函数. print self.tag,self.value #同上.class Word(Token): lexeme="" def __init__(self,t,s): Token.__init__(self,t) self.lexeme=s def tokenprint(self): print ("%d,%s")%(self.tag,self.lexeme)#同上class Lexer(): line=1 peek=' ' words={} def printall(self): #打印所有的保留字、标识符。 if len(self.words): for x in self.words.keys(): m=self.words[x].tokenprint() #忽略其中None的内容。 if m: print m def reserve(self,word): #之所以选python重写,是因为python里的dictionary与java程序中的Hashtable()是一家. self.words[word.lexeme]=word def __init__(self): self.reserve(Word(Tag.TRUE,"true")) self.reserve(Word(Tag.FALSE,"false")) self.reserve(Word(Tag.COMPARE,"==")) self.reserve(Word(Tag.COMPARE,">=")) self.reserve(Word(Tag.COMPARE,"<=")) self.reserve(Word(Tag.COMPARE,"!=")) self.reserve(Word(Tag.COMPARE,">")) self.reserve(Word(Tag.COMPARE,"<")) def scan(self,str_line): buf=str_line index=0 char=buf[index] while(char): if char==' ' or char=='\t': index+=1 char=buf[index] elif char=='#' or char=='/' and buf[index+1]=='/' or char=='/' and buf[index+1]=='*': buf=new_line(buf[index:]) index=0 char=buf[index] elif char=='\n': self.line+=self.line index+=1 char=buf[index] else: break #python的[]好好用呀! buf=buf[index:] if isDigit(buf[0]) or buf[0]=='.': #for 也好用. v=parse_float_num(buf) v=Num(v) v.tokenprint() return v if isLetter(buf[0]): b="" for x in buf: if isLetterOrDigit(x): b+=x else:break #高级语言的特性 if b in self.words.keys(): return self.words[b] else: w=Word(Tag.ID,b) self.words[b]=w return w if isComparison(buf[0]): v="" #for 也好用. for x in buf: if isComparison(x): v+=x else:break if v in self.words.keys(): return self.words[v] else: w=Word(Tag.COMPARE,v) self.words[v]=w return w t=Token(buf[0]) return t#测试 .忽略行首连续空白字符;x=Lexer()x.scan(" true")x.scan(" <>")x.scan(" /**/<")x.scan(''' /**/.123445''')x.printall() |